Addressing of GPGPU
Unified Memory Addressing (UMA)
In contemporary computational architecture, the significance of the GPU software ecosystem far outweighs the emphasis placed on hardware performance. Despite the predominant focus of research efforts on enhancing GPU performance metrics, the aspect of programmability remains critically overlooked. Programmability is fundamental to the establishment and evolution of a robust software ecosystem. Specifically, addressing mechanisms in GPUs serve as a pivotal interface for programming practices and memory management strategies. The progression towards greater programming ease has seen the transition from physical addressing to virtual addressing, culminating in the current paradigm of unified memory addressing. This study endeavors to explore both the hardware and software facets inherent to unified addressing, aiming to furnish a deeper understanding of its implications and applications within the realm of GPU architectures.
Following code snippet shows how unified memory address simplifies the program:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
#include <iostream>
#include <math.h>
// CUDA kernel to add elements of two arrays
__global__
void add(int n, float *x, float *y) {
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
int main(void) {
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory -- accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Launch kernel on 1M elements on the GPU, NO need to copy data to GPU
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y); //Using the same X/Y pointer
// Wait for GPU to finish before accessing on host, NO need to copy data from GPU
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
Besides simplifying programming, UMA also provides following benefits:
- Enable Large Data Models: supports oversubscribe GPU memory Allocate up to system memory size.
- Simpler Data Access: CPU/GPU Data coherence Unified memory atomic operations.
- Performance Turning with prefetching: Usage hints via cudaMemAdvise API Explicit prefetching API.
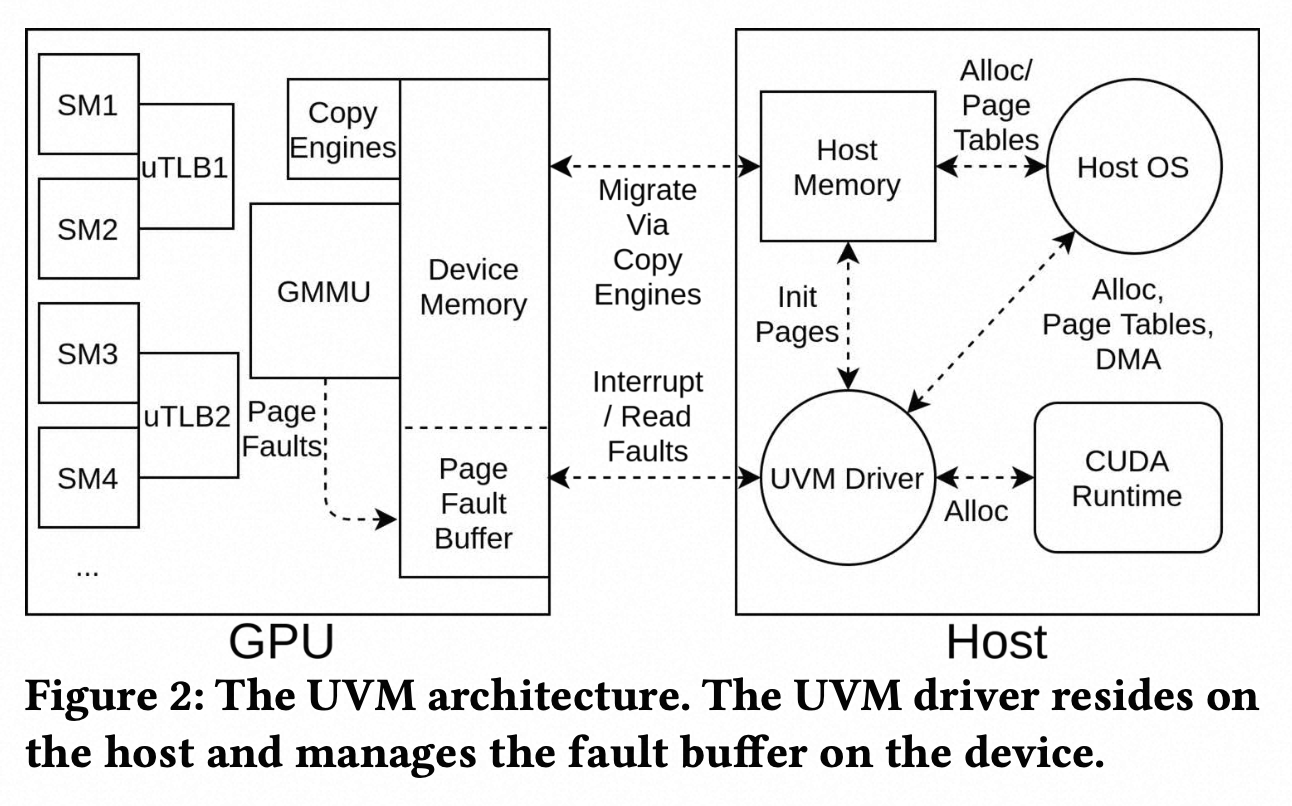
The underlying hardware architecture are illustrated in following diagram (Allen & Ge, 2021).
-
Page Fault propagates to the GPU memory management unit (GMMU), which sends a hardware interrupt to the host. The GMMU writes the corresponding fault information into the GPU Fault Buffer (circular buffer, configured and managed by the UVM driver).
-
GPU sends an interrupt over the interconnect to alert the host UVM driver of a page fault, the host retrieves the complete fault information from the GPU Fault Buffer.
-
Host instructs the GPU to copy pages into its memory via hardware copy engine, and update the page tables.
-
Host instructs the GPU to ‘replay’ the fault, causing uTLB to fetch the page table in GPU DRAM.
Addressing for Scaling
In contemporary computational environments, the capabilities for Scaling Up and Scaling Out constitute critical features for modern Graphics Processing Units (GPUs). Although NVIDIA has pioneered solutions such as NVLink and NVSwitch to address scalability, there remains a notable absence of an open industry standard for connecting GPUs through ultra-efficient interconnects. Addressing this gap, two emerging initiatives—the UALink consortium and the UltraEthernet Consortium (UEC)—are actively working towards overcoming these scalability challenges. These organizations have meticulously defined the hardware specifications and communication protocols necessary for such advancements. However, their frameworks offer limited discourse on addressing schemes and software programming paradigms. This post aims to propose a potential addressing strategy tailored to mainstream parallel and distributed programming models.
Parallel Programming Models
There are two parallel programming models in large distributed system: shared memory (SHMEM) and Message Passing Interface (MPI), as illustrated in follow diagram.
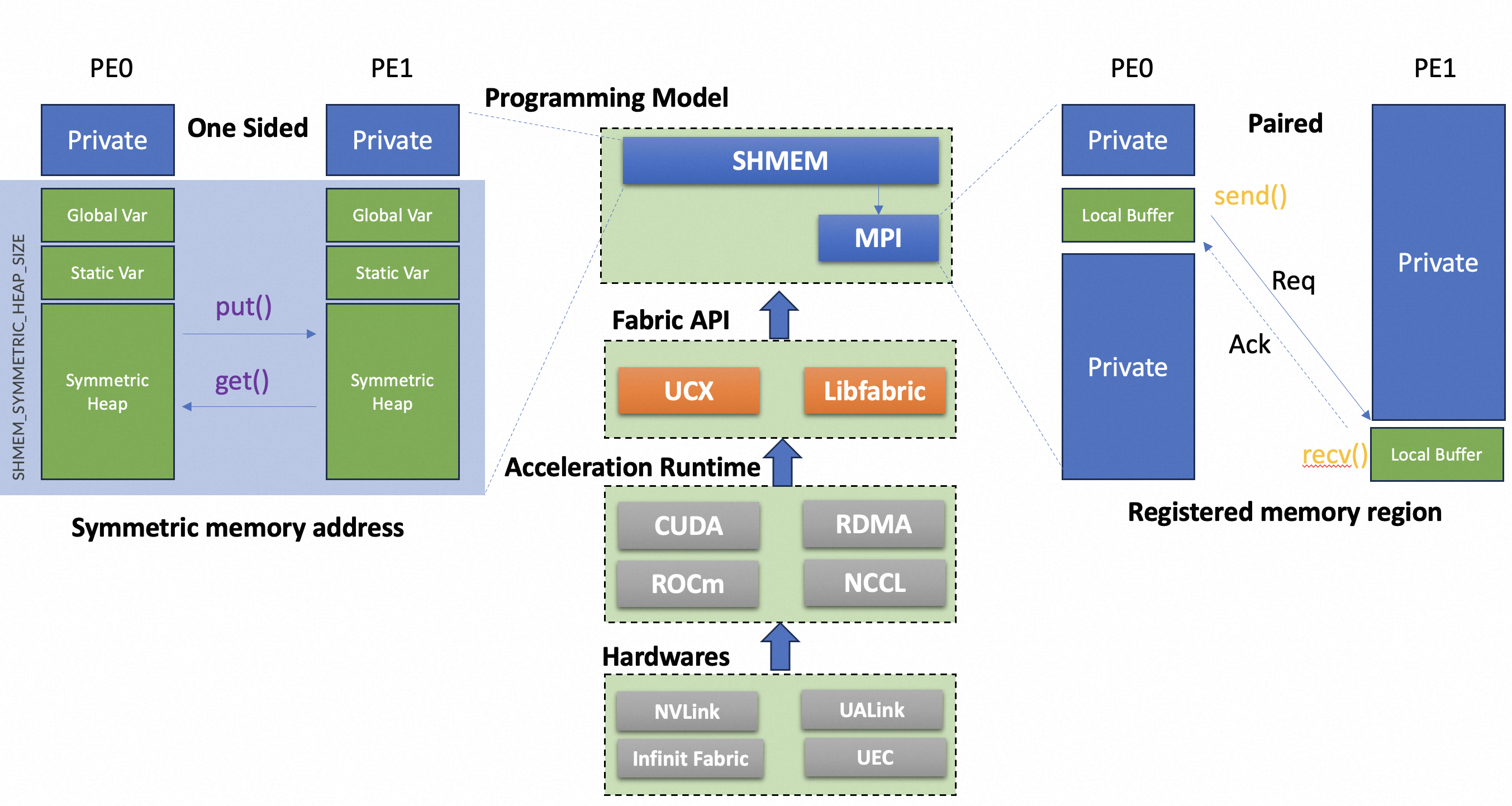
SHMEM
- Shared data are allocated in Symmetric Heap, but each PE manages its memory and the allocated buffer are different virtual address. Only size and alignment are coherent between PEs.
- Memory are accessed using One Sided api, which means remote nodes is not aware when and who is access the shared memory.
MPI
- No shared memory, only local buffer is used for temporary storage.
- Memory are accessed using Two Sided api, which means remote nodes needs to acknowledge the transaction.
Fabric API:
Libraries that aim to provide low-level, high-performance communication interfaces for applications in high-performance computing (HPC), cloud, data analytics, and other fields requiring efficient network communication.
- UCX: https://openucx.org/, unified API that handles many of the complexities of multi-transport environments.
- Libfabic: https://ofiwg.github.io/libfabric/, Fine-grained control over their network operations.
Scaling Systems
This diagrams shows a general scaling system:
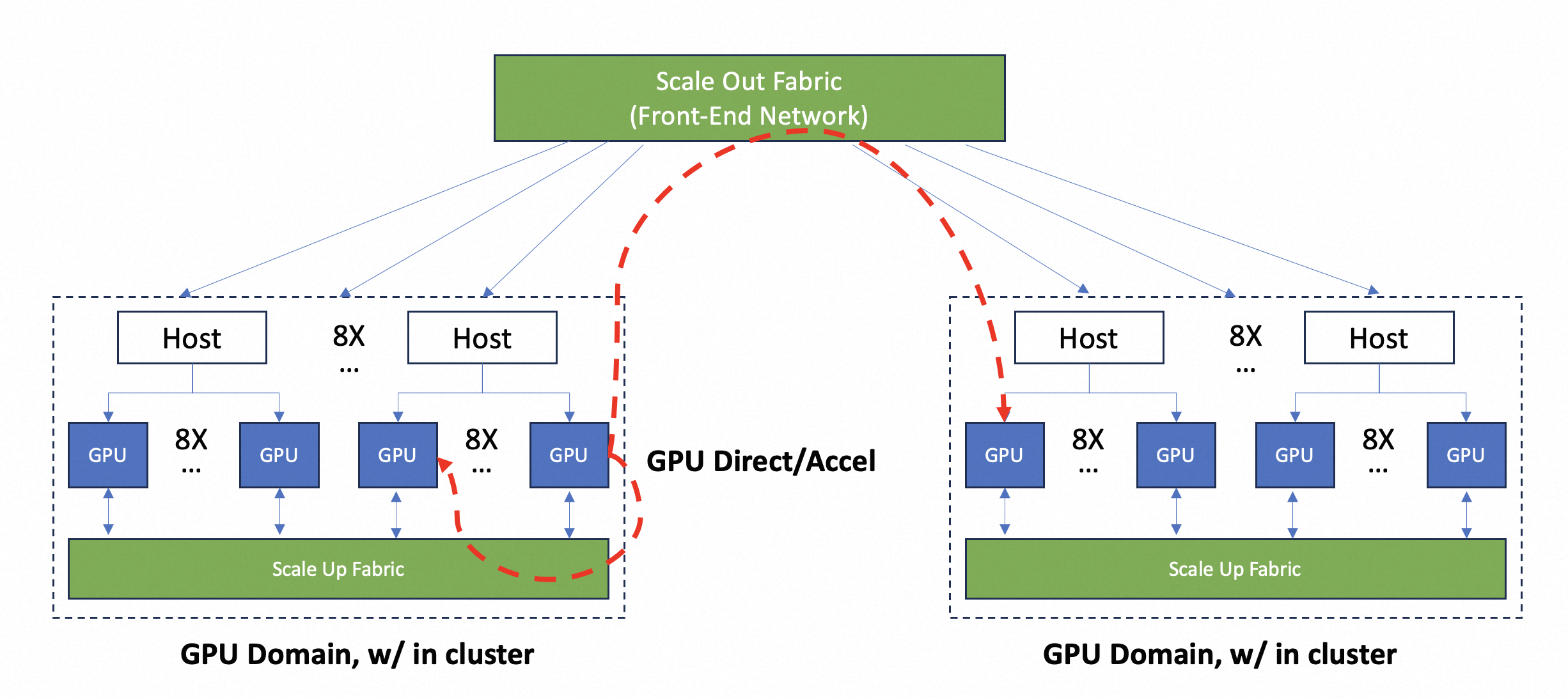
Scaling Up Scaling up means integrating more GPUs in a GPU domain, which shares a single unified memory address space. A typical scaling up system consists of multiple Hosts and GPUs.
- GPU Domain: direct GPU to GPU communication domain, via NVLink/NVSwitch/UALink/UEC etc.
- Host: 8X GPU/Host
Scaling Out Scaling out means more GPU domains connected by high speed network, but with different memory address space.
- Host to Host communication, via high speed ethernet fabric or InfiniBand.
Addressing in Scaling Up
Recent scaling up system incorporates unified memory addressing (e.g., UALink), to facilitate remote memory access, especially small data type accesses (such as word or double word). But this not necessary in distributed programme model.
In a shared memory programming model, illustrated in following diagram, we suppose the GPU/GPU are connected with build-in Ethernet Controllers and Ethernet switches.
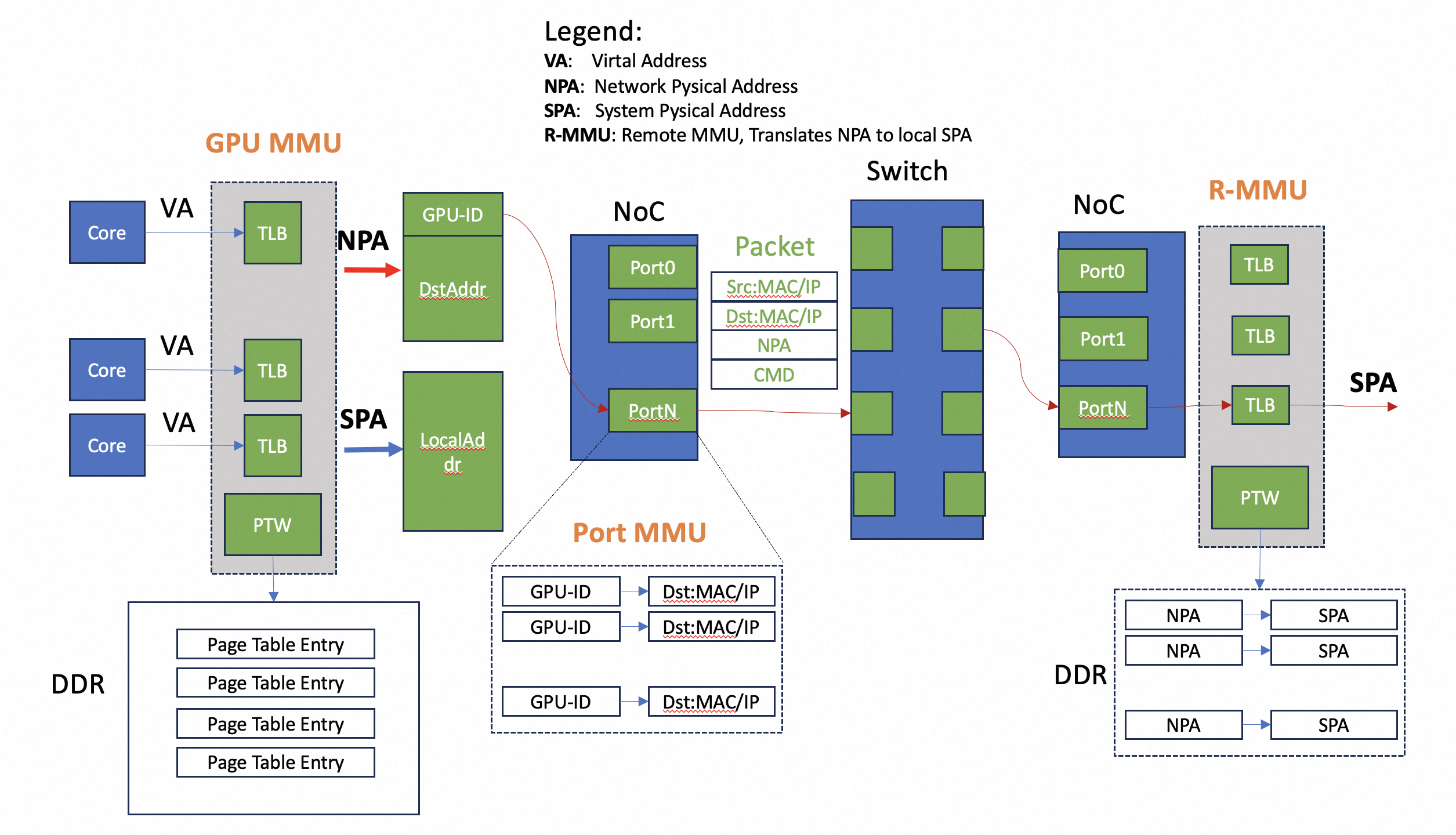
The scaling up system uses two types of addressing:
- System Physical Address: which is mapped to local GPU physical memories, like HBM.
- Network Physical Address: which is mapping to remote GPU. The NPA contains the GPU ID that will be used to find the correct MAC address of the destination GPU.
Addressing importing and exporting
In scaling up and scaling out system, the GPU under the same OS has is own private virtual address space, and not remote access is not allowed. The setup remote memory access, the remote GPU must export part of its memory, and other GPU must import this memory to its own address space.
These export and import involves multiple soft modules. A memory handle is used to pass the information between these modules. For example in HIP programming, hipIpcMemHandle_t is defined for these purpose:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#define hipIpcMemLazyEnablePeerAccess 0x01
#define HIP_IPC_HANDLE_SIZE 64
// The structure of remote memory handle.
typedef struct hipIpcMemHandle_st {
char reserved[HIP_IPC_HANDLE_SIZE];
} hipIpcMemHandle_t;
//Internal structure of IPC memory handle.
#define IHIP_IPC_MEM_HANDLE_SIZE 32
typedef struct ihipIpcMemHandle_st {
char ipc_handle[IHIP_IPC_MEM_HANDLE_SIZE]; ///< ipc memory handle on ROCr
size_t psize;
size_t poffset;
int owners_process_id;
char reserved[IHIP_IPC_MEM_RESERVED_SIZE];
} ihipIpcMemHandle_t;
- export:
When a remote GPU whens to export a memory region, it calls hipIpcGetMemHandle() to get an memory handle, and passed it to other GPUs that wants to import the memory.
1
2
// export the local device memory, which then be passed to other GPUs for remote access.
hipError_t hipIpcGetMemHandle(hipIpcMemHandle_t* handle, void* devPtr);
- import:
The GPU which wants to import the memory calls hipIpcOpenMemHandle to import the remote gpu address space:
1
2
3
// Maps memory exported from another process with hipIpcGetMemHandle into the current device address space.
// hipIpcMemHandles from each device in a given process may only be opened by one context per device per other process.
hipError_t hipIpcOpenMemHandle(void** devPtr, hipIpcMemHandle_t handle, unsigned int flags);
- close:
After remote GPU used the remote memory, it calls hipIpcCloseMemHandle to delete the remote gpu address space from its own address space:
1
2
//close the imported remote memory handle.
hipError_t hipIpcCloseMemHandle(void* devPtr);
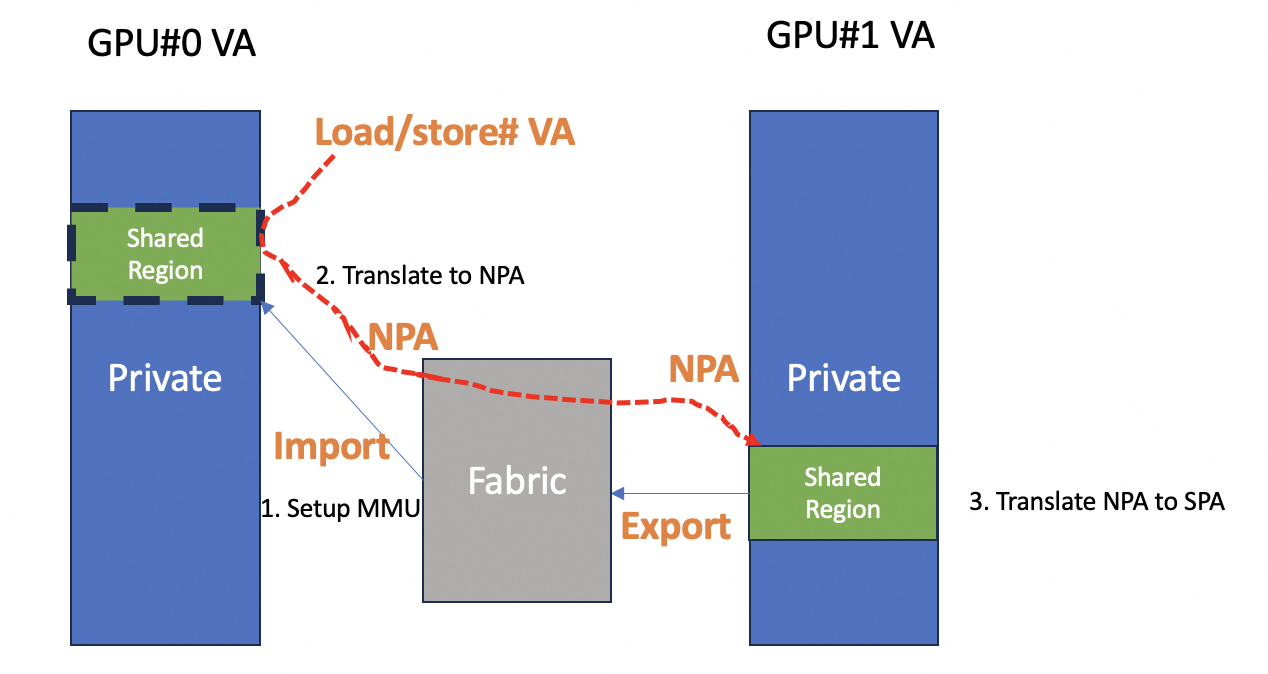
During these import/export and the following remote memory process, these MMUs are involved: Three MMUs are used during GPU to GPU communication:
- GPU MMU: setup the TLB table during import, and translate translate virtual address to NPA.
- Port MMU: A table in Ethernet controller, or just a software implementation which maps GPU-ID to network MAC address.
- R-MMU:Target GPU MMU translate NPA to local SPA, also do accessible control and checks.
Addressing mapping in Shared Programming Model
In shared memory programming model, the MMU setup and translation process can be described as Following:
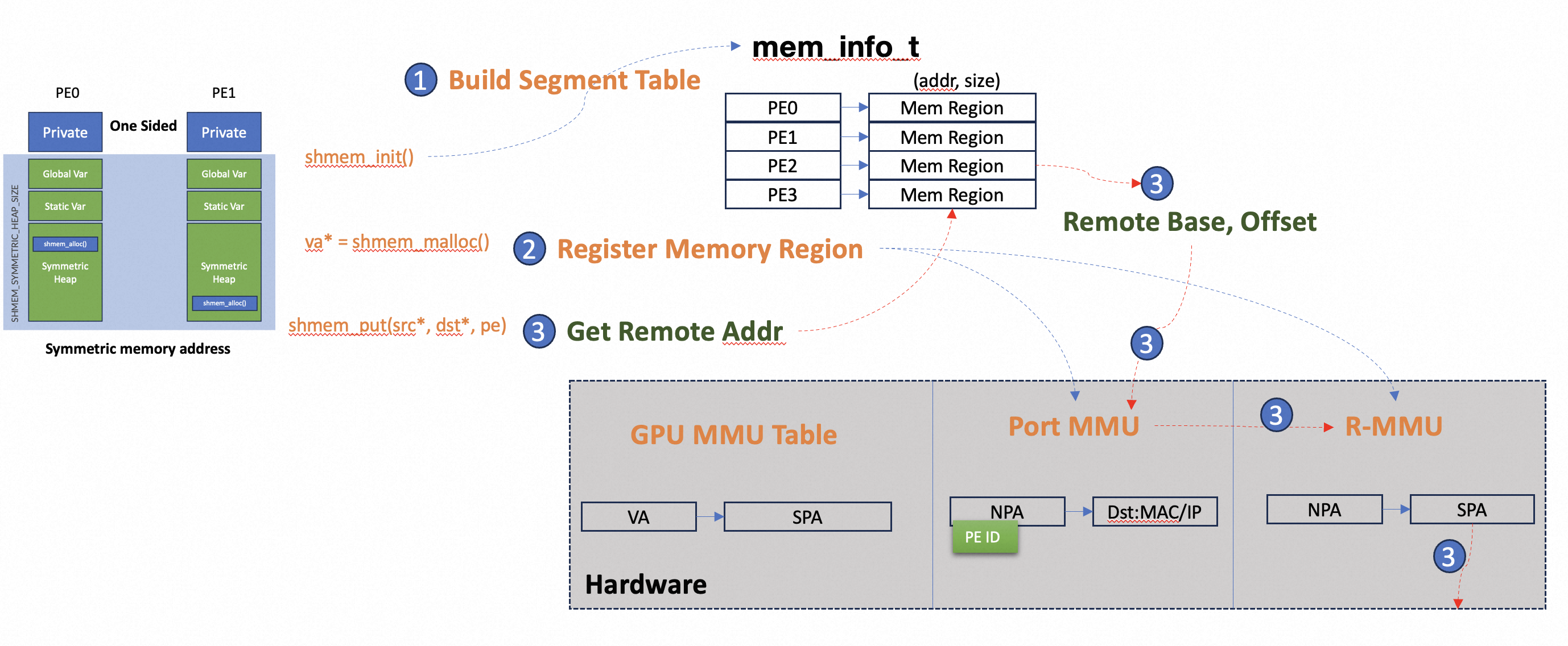
-
shmem_init(): The Shared Memory library will build up a segment table first, which will record the shared memory segments, including the start address and size. This table is shared between all PEs and will be referenced when accessed remotely.
- shmem_malloc(): User programming applies memories in the Symmetric shared heap.
- All PE will do the same malloc() action and the shmem_malloc() will only return after all PE completes its operation.
- shmem_malloc() returns Local Virtual Address and different PE returns different VA, this VA only valid in this PE.
- The library will register the allocated memory regions in *R-MMU, so remote access are allowed for this memory region, and **PIN the corresponding physical pages so OS won’t swap out the pages.
- shmem_access(): User program access remote memory via Local Virtual Address returned by malloc() and destination PE ID:
- Symmetric Offset are calculated using segment table and local VA.
- Remote VA are generated using segment table and Symmetric Offset.
- Network Packet are composed using remote VA, data and command.
- Remote PE: Remote PE parsed the network packet, extract the remote VA as its local VA, and do the accesses. local VA are then translated to physical address with R-MMU.
Reference
2021
- In-depth analyses of unified virtual memory system for GPU accelerated computingIn Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021
Enjoy Reading This Article?
Here are some more articles you might like to read next: